Understanding what is a serverless API backend requires a shift in perspective from traditional server-based architectures. This approach leverages the power of cloud computing to execute code without the need for managing underlying infrastructure. This eliminates the operational overhead associated with server provisioning, maintenance, and scaling, allowing developers to focus on building and deploying applications.
Serverless API backends, at their core, are composed of several key components. These include API gateways that act as the entry point for client requests, serverless functions that execute the application logic, and databases for persistent data storage. This architecture is fundamentally different from traditional approaches, offering benefits like automatic scaling, cost efficiency, and increased developer productivity. We will explore these components and benefits in detail.
Introduction to Serverless API Backends
Serverless API backends represent a paradigm shift in application development, offering a way to build and deploy APIs without managing the underlying infrastructure. This approach allows developers to focus on writing code and business logic, rather than dealing with server provisioning, scaling, and maintenance. This introduction will detail the core concepts, benefits, and fundamental definition of serverless computing in the context of API development.
Core Concept of Serverless API Backends
The central idea behind a serverless API backend is that the cloud provider manages the server infrastructure, including provisioning, scaling, and maintenance. Developers deploy individual functions, often called “functions as a service” (FaaS), which are triggered by events, such as HTTP requests to an API endpoint. These functions execute in response to these triggers and handle the processing of the API requests.
The cloud provider automatically scales the resources allocated to these functions based on demand, ensuring optimal performance and cost efficiency. This contrasts with traditional server-based architectures, where developers are responsible for managing and scaling servers.
Benefits of Using a Serverless Approach
Serverless API backends offer several advantages over traditional server-based architectures. These benefits contribute to faster development cycles, reduced operational overhead, and improved cost management.
- Reduced Operational Overhead: The cloud provider handles server management tasks, including patching, security updates, and scaling. This frees developers from these responsibilities, allowing them to concentrate on application development.
- Automatic Scaling: Serverless platforms automatically scale the resources allocated to functions based on the incoming traffic. This ensures that the API can handle varying loads without manual intervention. For example, if an API experiences a sudden surge in requests, the platform automatically allocates more resources to handle the increased demand.
- Cost Efficiency: Serverless platforms typically employ a pay-per-use pricing model, where users are charged only for the actual compute time and resources consumed. This can result in significant cost savings compared to traditional server-based architectures, where resources are often provisioned and paid for even when idle.
- Faster Development Cycles: The focus on individual functions and event-driven architectures can accelerate development cycles. Developers can quickly deploy and iterate on individual functions without affecting the entire API.
- Improved Scalability and Availability: Serverless platforms are designed to be highly scalable and available. The automatic scaling capabilities and the distributed nature of serverless architectures ensure that the API can handle large amounts of traffic and remain available even in the event of failures.
Definition of Serverless Computing
Serverless computing is a cloud computing execution model where the cloud provider dynamically manages the allocation of machine resources. The developer is not required to manage servers. The cloud provider manages the infrastructure, and the developer only pays for the actual compute time consumed by the application.
Serverless computing = FaaS + Backend as a Service (BaaS)
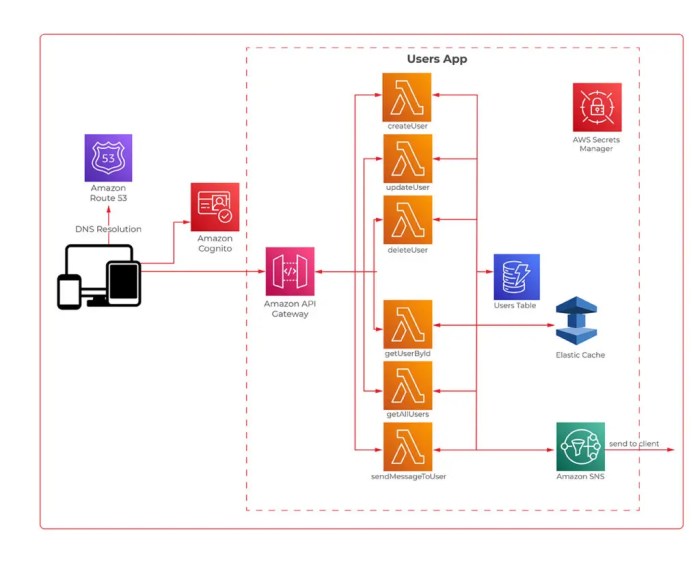
Key Components of a Serverless API Backend
Building a serverless API backend involves a constellation of interconnected services, each playing a crucial role in handling requests, processing data, and delivering responses. These components work in concert to provide a scalable, cost-effective, and resilient architecture. Understanding these core elements is fundamental to designing and implementing serverless applications.
API Gateway
The API Gateway acts as the entry point for all client requests, providing a single, unified interface to the backend services. It manages routing, authentication, authorization, and rate limiting. The gateway abstracts the complexities of the underlying serverless infrastructure, presenting a clean and manageable API to the outside world.
- Request Routing: The API Gateway directs incoming requests to the appropriate backend functions based on the request path, method, and other criteria. This routing mechanism is typically configured using rules defined in the gateway’s configuration.
- Authentication and Authorization: The gateway handles user authentication, verifying the identity of the requestor. It also enforces authorization policies, determining whether a user has the necessary permissions to access a specific resource. Common authentication mechanisms include API keys, OAuth, and JWT (JSON Web Tokens).
- Rate Limiting: To prevent abuse and ensure service availability, the API Gateway implements rate limiting, controlling the number of requests allowed from a particular client within a specified time period. This helps to protect backend functions from being overwhelmed.
- Request Transformation: The gateway can transform incoming requests, such as modifying headers, converting data formats, or validating request bodies. This allows the backend functions to focus on core business logic.
- Response Transformation: Similarly, the gateway can transform responses from the backend functions before returning them to the client. This may involve modifying headers, formatting data, or masking sensitive information.
Functions
Serverless functions, also known as Function-as-a-Service (FaaS), are the workhorses of the serverless architecture. They are self-contained units of code that execute in response to specific events, such as API requests. Functions are stateless, meaning they do not maintain any persistent state between invocations.
- Event-Driven Execution: Functions are triggered by events, such as HTTP requests, database changes, or scheduled timers. The event data provides the context for the function’s execution.
- Statelessness: Functions are designed to be stateless, meaning they do not store any data between invocations. This simplifies scaling and allows for parallel execution.
- Scalability: The serverless platform automatically scales the number of function instances based on the incoming request load. This ensures that the API can handle traffic spikes without manual intervention.
- Concurrency: Multiple instances of a function can execute concurrently to handle parallel requests, improving overall performance.
- Cost Efficiency: Functions are only charged for the actual execution time, making them a cost-effective solution for intermittent workloads.
Databases
Databases provide persistent storage for the data used and managed by the API. Serverless architectures often leverage managed database services that offer scalability, high availability, and automatic backups. The choice of database depends on the specific requirements of the application, including data structure, query patterns, and performance needs.
- Data Storage: Databases store and organize the data used by the API. This data can include user information, product details, order history, and any other information required by the application.
- Data Models: Databases employ different data models, such as relational (SQL), NoSQL (document, key-value, graph, etc.), to organize data. The choice of data model depends on the structure of the data and the query patterns required.
- Scalability and Performance: Managed database services offer features like automatic scaling and caching to ensure that the database can handle increasing data volumes and traffic loads.
- High Availability and Durability: Databases provide high availability through features like replication and failover mechanisms. They also offer data durability through backups and other data protection strategies.
- Database Interactions: Functions interact with the database to read, write, and update data. This interaction is typically performed using database-specific SDKs or libraries.
Visual Representation of a Serverless API Backend
The following describes a visual representation of a typical serverless API backend.Imagine a diagram that depicts the flow of requests and data within a serverless API backend. At the top, we have a box labeled “Client (e.g., Web/Mobile App),” representing the source of API requests.Below this, a large rectangular box labeled “API Gateway” is the central component. This box has arrows pointing towards it from the “Client” box, indicating that the API Gateway receives all incoming requests.
Inside the “API Gateway” box, there are labels indicating its functions: “Routing,” “Authentication,” “Authorization,” and “Rate Limiting.”Below the “API Gateway,” multiple smaller rectangular boxes represent serverless functions. Each function box is labeled with a descriptive name, such as “CreateUserFunction,” “GetProductDetailsFunction,” and “UpdateOrderFunction.” Arrows emanate from the “API Gateway” to these function boxes, demonstrating that the gateway routes requests to the appropriate functions.Each function box is connected to a database component.
A database component, which is a rectangular box, is labeled “Database” and further specifies different types of databases like “DynamoDB” (for NoSQL), or “PostgreSQL” (for SQL). The arrows indicate that the functions interact with the database to read and write data.Finally, arrows point from the function boxes back to the “API Gateway,” showing that the functions return responses to the gateway.
The “API Gateway” then sends these responses back to the “Client,” completing the request-response cycle. The entire diagram is designed to illustrate the flow of data, from client request to database interaction and back to the client, highlighting the roles of each component in a serverless API backend.
Advantages of Serverless APIs
Serverless APIs present a compelling paradigm shift in software development, offering significant advantages over traditional server-based architectures. These benefits stem from the inherent characteristics of serverless computing, which enable developers to focus on code rather than infrastructure management. This section will delve into the key advantages, including scalability, cost-effectiveness, and reduced operational overhead, comparing serverless models to traditional deployments and providing concrete examples of their performance in handling variable workloads.
Scalability and Elasticity
Serverless APIs exhibit exceptional scalability, automatically adjusting to fluctuating demand. This elasticity is a core tenet of serverless architecture, eliminating the need for manual scaling or capacity planning.To illustrate:* Automatic Scaling: Serverless platforms, such as AWS Lambda, Azure Functions, and Google Cloud Functions, automatically allocate compute resources based on incoming requests. When traffic increases, the platform provisions additional instances of the function, ensuring consistent performance without manual intervention.
No Capacity Planning
Developers no longer need to predict peak traffic or provision servers with excess capacity to handle potential spikes. The serverless platform handles the scaling automatically, providing resources as needed.
Horizontal Scaling
Serverless scaling is inherently horizontal. Multiple instances of the function are deployed concurrently to handle the load, as opposed to vertical scaling, which involves increasing the resources of a single server.The result is a highly responsive and resilient API that can handle traffic spikes without performance degradation.
Cost-Effectiveness
Serverless APIs offer a cost-effective alternative to traditional server deployments, primarily through a pay-per-use pricing model. This model significantly reduces operational expenses, especially for applications with variable workloads.Consider the following:* Pay-Per-Use Pricing: Serverless platforms charge only for the actual compute time used, the number of requests, and the resources consumed (e.g., memory, storage). This contrasts with traditional deployments, where developers pay for provisioned resources, regardless of utilization.
Reduced Infrastructure Costs
Serverless eliminates the need for server provisioning, maintenance, and management. This frees up resources and reduces the associated costs.
Optimized Resource Utilization
Serverless functions are only active when invoked. This minimizes idle time and the associated costs.The cost savings are particularly pronounced for applications with unpredictable or spiky traffic patterns. For instance, a website that experiences occasional surges in traffic during product launches would benefit significantly from the pay-per-use model, avoiding the costs of maintaining idle servers during off-peak hours.
Reduced Operational Overhead
Serverless APIs significantly reduce operational overhead by abstracting away infrastructure management tasks. This allows developers to focus on building and deploying code rather than managing servers, security, and other operational aspects.This reduction manifests in several key areas:* Automated Infrastructure Management: Serverless platforms handle server provisioning, patching, scaling, and monitoring automatically.
Simplified Deployment
Deploying serverless functions is typically a streamlined process, often involving uploading code and configuring triggers.
Reduced Security Burden
Serverless platforms often provide built-in security features, such as identity and access management, reducing the security burden on developers.
Automated Monitoring and Logging
Serverless platforms provide built-in monitoring and logging capabilities, simplifying troubleshooting and performance analysis.This reduced operational overhead translates to faster development cycles, increased developer productivity, and reduced risk of operational errors. The elimination of infrastructure management allows development teams to allocate their resources more effectively, focusing on core business logic and innovation.
Cost Model Comparison: Serverless vs. Traditional
A clear understanding of the cost models for serverless and traditional deployments is crucial for making informed architectural decisions.A tabular comparison helps clarify the key differences:
| Feature | Serverless | Traditional |
|---|---|---|
| Pricing Model | Pay-per-use (compute time, requests, resources) | Fixed cost (provisioned resources) |
| Resource Allocation | Automatic, on-demand | Manual, pre-provisioned |
| Scalability | Automatic, elastic | Manual or auto-scaling (requires configuration) |
| Operational Overhead | Low (platform managed) | High (server management, patching, etc.) |
| Idle Time Costs | Zero (functions only run when invoked) | Significant (servers run continuously) |
This table highlights the key differences, showcasing how serverless models offer cost advantages, especially when considering applications with fluctuating workloads. The fixed costs associated with traditional deployments can be a significant disadvantage for applications that experience periods of low traffic.
Handling Sudden Traffic Spikes
Serverless APIs excel at handling sudden traffic spikes, providing a robust and reliable experience for users. The automatic scaling capabilities of serverless platforms are the key to this resilience.Consider a hypothetical scenario:* Scenario: A popular e-commerce website launches a new product, generating a sudden surge in traffic to the API that provides product information.
Serverless Response
The serverless platform automatically detects the increased load and rapidly provisions additional instances of the API function. These instances handle the incoming requests concurrently, ensuring that users experience minimal latency and no service degradation.
Traditional Response
In a traditional deployment, the website’s servers might struggle to handle the sudden load, leading to slow response times, errors, and a poor user experience. Manual scaling would be required, potentially leading to downtime or service interruptions while the infrastructure is scaled up.This ability to automatically scale up during traffic spikes is a critical advantage of serverless APIs, ensuring a seamless user experience even during periods of high demand.
The ability to absorb traffic spikes without manual intervention makes serverless APIs a highly resilient and reliable choice for various applications.
Serverless API Backend Architectures
Serverless API backend architectures offer diverse design patterns to accommodate various application needs. These architectures leverage cloud provider services to minimize operational overhead, enhance scalability, and reduce costs. The choice of architecture depends heavily on the application’s specific requirements, including its functionality, data access patterns, and anticipated traffic volume. Selecting the most appropriate architecture is critical for optimal performance and resource utilization.
Common Serverless API Backend Architectures
Several prevalent architectural patterns are employed in serverless API backends. Each pattern has its strengths and weaknesses, making them suitable for different use cases. Understanding these patterns is crucial for making informed architectural decisions.
- Event-Driven Architecture: This architecture centers around asynchronous communication triggered by events. When an event occurs, such as a new item being added to a database, a corresponding function is triggered to process that event. This design promotes loose coupling between services and enhances scalability. For instance, in an e-commerce application, adding a product to a cart could trigger a function to update inventory levels, send a notification to the user, and initiate a recommendation service update.
- Microservices Architecture: This approach decomposes an application into a collection of small, independent services, each responsible for a specific business function. Each microservice can be developed, deployed, and scaled independently. Serverless functions often implement these microservices, allowing for fine-grained scaling and resource allocation. An example includes an e-commerce platform where separate microservices manage user authentication, product catalogs, order processing, and payment gateways.
- API Gateway-Driven Architecture: An API gateway acts as a central entry point for all API requests. It handles tasks such as authentication, authorization, routing, and rate limiting. Serverless functions are typically deployed behind the API gateway, allowing the gateway to manage traffic and security. This architecture simplifies API management and provides a single point of control. This is beneficial when exposing multiple backend services through a unified API, as the gateway can route requests to the appropriate service based on the request’s path or method.
- Data-Driven Architecture: This architecture emphasizes data as the central element, where serverless functions react to changes in data stores. For example, when data is written to a database, a function is triggered to perform operations like data validation, aggregation, or integration with other systems. This approach is well-suited for applications with heavy data processing requirements. A social media application, for instance, can use a data-driven architecture to trigger functions that analyze user posts for sentiment analysis or content moderation.
API Architecture for a Basic To-Do List Application
A basic to-do list application provides a simple yet illustrative example of how a serverless architecture can be applied. The application will support creating, reading, updating, and deleting (CRUD) tasks. The architecture will utilize various serverless services to handle different aspects of the application’s functionality.
The core components and their functions will be organized as follows:
| Service | Function | Technology |
|---|---|---|
| API Gateway | Handles API requests, authentication, and routing. | AWS API Gateway |
| Task Creation Function | Creates new to-do tasks and stores them in the database. | AWS Lambda, Node.js |
| Task Retrieval Function | Retrieves tasks based on user ID. | AWS Lambda, Node.js |
| Task Update Function | Updates existing tasks in the database. | AWS Lambda, Node.js |
| Task Deletion Function | Deletes tasks from the database. | AWS Lambda, Node.js |
| Database | Stores task data. | AWS DynamoDB |
| Authentication Service | Manages user authentication and authorization. | AWS Cognito |
In this architecture, the API Gateway receives all incoming requests. It then routes these requests to the appropriate Lambda function, which handles the specific CRUD operation. DynamoDB is used as a NoSQL database to store the to-do list data. AWS Cognito manages user authentication, ensuring secure access to the application. This architecture promotes scalability, as each Lambda function can scale independently based on the workload.
Furthermore, it minimizes operational overhead, as the cloud provider manages the underlying infrastructure.
Choosing a Serverless Platform
The selection of a serverless platform is a pivotal decision in designing and deploying a serverless API backend. This choice significantly impacts development effort, operational costs, scalability, and overall system performance. Careful consideration of platform features, pricing models, and vendor ecosystems is crucial for aligning the platform with project requirements and long-term goals.
Popular Serverless Platforms
Several serverless platforms have gained significant traction in the industry, each offering a unique set of features and capabilities. These platforms provide the infrastructure and services required to execute code without managing servers.* AWS Lambda: A compute service that lets you run code without provisioning or managing servers. It automatically scales to handle incoming requests and supports multiple programming languages.
Google Cloud Functions
An event-driven, serverless compute platform that allows you to create functions triggered by events from various sources, such as HTTP requests, Cloud Storage changes, and Pub/Sub messages.
Azure Functions
A serverless compute service that enables you to run event-triggered code without managing infrastructure. It supports a wide range of programming languages and triggers, integrating seamlessly with other Azure services.
Platform Feature and Pricing Model Comparison
A comparative analysis of features and pricing models is essential for informed platform selection. This section will compare AWS Lambda, Google Cloud Functions, and Azure Functions.
| Feature | AWS Lambda | Google Cloud Functions | Azure Functions |
|---|---|---|---|
| Supported Languages | Node.js, Python, Java, Go, C#, Ruby, PowerShell, and more (through custom runtimes) | Node.js, Python, Go, Java, .NET, and more (through custom runtimes) | C#, F#, Node.js, Python, Java, PowerShell, PHP, and more (through custom runtimes) |
| Invocation Trigger | HTTP requests, API Gateway, S3 events, DynamoDB streams, and more | HTTP requests, Cloud Storage, Cloud Pub/Sub, Cloud Firestore, and more | HTTP requests, Azure Blob Storage, Azure Cosmos DB, Azure Event Hubs, and more |
| Concurrency Control | Configurable concurrency limits and provisioned concurrency | Automatic scaling based on demand | Configurable concurrency limits and dynamic scaling |
| Pricing Model | Pay-per-use based on compute time, memory allocation, and requests | Pay-per-use based on compute time, memory allocation, and requests | Pay-per-use based on compute time, memory allocation, and executions |
| Maximum Execution Time | 15 minutes (configurable) | 9 minutes (configurable) | 10 minutes (configurable, with Premium plan up to unlimited) |
| Integration with other Services | Extensive integration with other AWS services (e.g., S3, DynamoDB, API Gateway) | Seamless integration with other Google Cloud services (e.g., Cloud Storage, Cloud Firestore, Cloud Pub/Sub) | Strong integration with other Azure services (e.g., Azure Blob Storage, Azure Cosmos DB, Azure Event Hubs) |
The pricing models of these platforms are generally pay-per-use. For example, AWS Lambda charges based on the number of requests, the duration of execution, and the amount of memory allocated. Google Cloud Functions and Azure Functions follow a similar pricing structure. However, the specific rates and free tiers can vary. For instance, AWS Lambda offers a generous free tier that includes a certain number of free requests and compute time each month, making it suitable for small projects or testing.
Google Cloud Functions and Azure Functions also provide free tiers, although the details may differ. Understanding these nuances is essential for cost optimization.
Factors for Selecting a Serverless Platform
Selecting the right serverless platform requires careful consideration of several factors. These factors ensure the platform aligns with project requirements, performance needs, and budget constraints.
- Programming Language Support: Assess the platform’s support for the programming languages used in the project. Ensure the platform offers native support or allows custom runtimes for the chosen languages.
- Trigger Options: Evaluate the available trigger options, such as HTTP requests, database events, and message queues. The chosen platform must support the required triggers to facilitate event-driven architecture.
- Integration Capabilities: Consider the platform’s integration capabilities with other services and tools. Seamless integration with databases, storage solutions, and API gateways can simplify development and deployment.
- Concurrency and Scalability: Evaluate the platform’s ability to handle concurrent requests and scale automatically. The platform should efficiently manage increasing workloads without manual intervention.
- Monitoring and Logging: Review the platform’s monitoring and logging features. Robust monitoring and logging capabilities are crucial for troubleshooting, performance analysis, and ensuring the reliability of the API backend.
- Pricing and Cost Optimization: Analyze the pricing models and compare the costs of different platforms. Consider the expected traffic volume, execution time, and memory usage to optimize costs.
- Vendor Lock-in: Evaluate the level of vendor lock-in associated with each platform. Consider the ease of migrating to a different platform in the future if necessary.
- Community and Support: Consider the platform’s community support and documentation. A strong community and readily available documentation can facilitate troubleshooting and accelerate development.
- Security Features: Assess the platform’s security features, including identity and access management, encryption, and compliance certifications. Ensure the platform meets the project’s security requirements.
- Execution Time Limits: Determine the maximum execution time allowed by the platform. The platform’s time limits should align with the expected execution time of the API functions.
API Gateway and Function Management

The API gateway is a critical component in a serverless API backend, acting as the central entry point for all client requests. Its primary function is to manage and route these requests to the appropriate serverless functions. Furthermore, it provides essential services like authentication, authorization, and rate limiting, thereby enhancing security and controlling resource consumption. The efficient management of the API gateway directly impacts the performance, scalability, and security of the entire API backend.
Role of an API Gateway in a Serverless API Backend
An API gateway serves as the single point of entry for all client interactions with the serverless API. It decouples the client from the underlying serverless functions, simplifying client development and enabling the backend to evolve independently. This abstraction layer allows for modifications to the backend logic, such as function updates or scaling, without impacting the client-side code.The API gateway also handles various crucial tasks, including:
- Routing: Directs incoming requests to the appropriate serverless functions based on the request’s path, method (GET, POST, etc.), and other criteria.
- Authentication and Authorization: Verifies the identity of the client and determines their access rights to specific resources.
- Rate Limiting: Controls the number of requests a client can make within a specific timeframe to prevent abuse and ensure fair resource allocation.
- Request Transformation: Modifies incoming requests, such as converting data formats or adding headers, before passing them to the backend functions.
- Response Transformation: Modifies the responses from the backend functions before sending them back to the client.
- Monitoring and Logging: Collects data about API usage, performance, and errors for monitoring and debugging purposes.
Configuring API Gateways to Route Requests to Different Functions
Configuring an API gateway involves defining routes that map incoming requests to specific serverless functions. This mapping is typically based on the request’s URL path, HTTP method, and potentially other parameters. The API gateway analyzes the incoming request and, based on the defined rules, invokes the corresponding function.The configuration process often involves the following steps:
- Defining the API endpoint: This involves specifying the base URL for the API.
- Creating routes: For each API endpoint, create routes that specify the path, HTTP method, and the associated serverless function.
- Configuring request parameters: Define how the API gateway will handle request parameters, such as query parameters or path parameters.
- Setting up authentication and authorization: Configure security mechanisms, such as API keys or OAuth, to protect the API.
- Implementing request and response transformations: If necessary, define how the API gateway will transform requests and responses.
The specifics of configuration vary depending on the chosen serverless platform. However, the core principles remain consistent across different platforms. For example, AWS API Gateway allows you to define routes and integrate them with Lambda functions using the AWS Management Console, the AWS CLI, or Infrastructure as Code (IaC) tools like Terraform. Google Cloud’s API Gateway offers similar functionalities, allowing you to define routes and connect them to Cloud Functions or other backend services.
Azure API Management provides analogous capabilities for managing APIs and routing traffic to Azure Functions.
Example: API Gateway Configuration for Authentication
Authentication is a crucial security aspect handled by the API gateway. The gateway can validate incoming requests against security credentials, such as API keys or tokens, before allowing access to the backend functions. This prevents unauthorized access and protects the API from malicious attacks. The following blockquote illustrates a hypothetical configuration using a JSON format to handle API key-based authentication.
This example depicts a configuration snippet, showcasing how an API gateway might handle authentication. It uses a simplified JSON format to demonstrate the principles involved. This is not a complete, runnable configuration but rather a conceptual representation.
"routes": [ "path": "/users", "method": "GET", "authorizer": "type": "API_KEY", "apiKeySource": "HEADER", "apiKeyName": "x-api-key", "apiKeyValidation": "apiKeyList": [ "YOUR_API_KEY_1", "YOUR_API_KEY_2" ] , "targetFunction": "getUserListFunction" , "path": "/users/userId", "method": "GET", "authorizer": "type": "API_KEY", "apiKeySource": "HEADER", "apiKeyName": "x-api-key", "apiKeyValidation": "apiKeyList": [ "YOUR_API_KEY_1", "YOUR_API_KEY_2" ] , "targetFunction": "getUserFunction" ]In this example:
- The
routesarray defines two routes:/usersand/users/userId.- Each route specifies the
pathandmethod(GET in this case).- The
authorizersection configures API key authentication.type: "API_KEY"indicates API key-based authentication.apiKeySource: "HEADER"specifies that the API key should be provided in thex-api-keyHTTP header.apiKeyName: "x-api-key"defines the name of the header.apiKeyValidationcontains a list of valid API keys (apiKeyList). In a real-world scenario, these keys would be securely stored and managed.targetFunctionspecifies the name of the serverless function to be invoked for each route.This configuration ensures that only requests with a valid API key in the
x-api-keyheader are allowed to access thegetUserListFunctionandgetUserFunction. The API gateway intercepts the request, validates the API key, and then invokes the appropriate function. If the API key is invalid or missing, the gateway rejects the request and returns an appropriate error response.
Data Storage in Serverless API Backends
Data storage is a critical component of any API backend, and serverless architectures are no exception. Choosing the right data storage solution significantly impacts performance, scalability, and cost-effectiveness. Serverless APIs often interact with various data stores to manage application state, user data, and other relevant information. The selection of the appropriate storage mechanism depends heavily on the specific requirements of the application, including data access patterns, data volume, and consistency needs.
Common Data Storage Options for Serverless APIs
Serverless APIs leverage a range of data storage options, each optimized for different use cases. These options are generally categorized based on their underlying data models and access patterns.
- Databases: Relational and NoSQL databases are frequently employed to store structured and unstructured data, respectively. These databases provide mechanisms for data persistence, querying, and management.
- Object Storage: Object storage services are designed to store large volumes of unstructured data, such as images, videos, and documents. They offer high durability, availability, and scalability.
- Key-Value Stores: Key-value stores are simple, fast data stores that map keys to values. They are suitable for caching, session management, and other scenarios where fast access to individual data items is essential.
- Caching Services: Caching services store frequently accessed data in-memory to reduce latency and improve application performance. They are often used in conjunction with databases to minimize database load.
Comparison of Database Options for Serverless Applications
Choosing the appropriate database is a crucial decision in designing a serverless API. The choice hinges on factors such as data structure, consistency requirements, scalability needs, and cost considerations. Different database types cater to various requirements.
- Relational Databases (SQL): Relational databases, such as PostgreSQL, MySQL, and Amazon RDS, are based on the relational model, organizing data into tables with predefined schemas. They offer strong consistency guarantees and are well-suited for applications with complex data relationships and transactional requirements. However, they can be more complex to manage and scale in a serverless environment compared to NoSQL options. They often require more configuration and setup for auto-scaling.
- NoSQL Databases: NoSQL databases encompass a variety of data models, including document, key-value, and graph databases. They offer greater flexibility in terms of data structure and often provide better scalability and performance compared to relational databases, particularly for read-heavy workloads. Popular NoSQL options for serverless include Amazon DynamoDB, MongoDB Atlas, and Azure Cosmos DB. They often provide features like automatic scaling and pay-per-request pricing, which align well with the serverless model.
- Document Databases: Document databases store data in JSON-like documents. They are flexible and well-suited for handling semi-structured data.
- Key-Value Databases: Key-value databases offer a simple data model and provide fast read/write operations. They are suitable for caching and session management.
- Graph Databases: Graph databases store data as nodes and edges, making them ideal for applications that involve relationships between data elements.
Connecting a Serverless Function to a Database
Connecting a serverless function to a database involves establishing a secure and efficient communication channel between the function and the data store. The specific implementation varies depending on the chosen platform and database technology, but the general principles remain consistent.
Here’s a simplified example to illustrate the process:
Step 1: Setting up the Database Connection
First, the serverless function needs to establish a connection to the database. This often involves using a database client library specific to the chosen database technology (e.g., a Python library for PostgreSQL or a Node.js driver for MongoDB). The connection details, such as the database host, port, username, and password, are typically configured through environment variables, allowing for secure management and easy modification without changing the function’s code.
Step 2: Writing Database Interaction Code
The serverless function then includes code to interact with the database. This involves writing queries to retrieve, insert, update, or delete data. The specific queries will depend on the application’s requirements and the chosen database’s query language (e.g., SQL for relational databases, or query languages specific to NoSQL databases). It’s essential to handle database connection errors and exceptions gracefully to ensure the function’s resilience.
Step 3: Secure Access and Authentication
Securing the database connection is paramount. This typically involves the following:
- Authentication: The serverless function must authenticate with the database using appropriate credentials.
- Authorization: The database user associated with the serverless function should have the minimal set of permissions required to perform its tasks, following the principle of least privilege.
- Network Security: Network security best practices should be implemented to limit access to the database. This might involve using VPC (Virtual Private Cloud) configurations to restrict database access to only authorized resources within a private network, preventing direct public access.
Step 4: Code Snippet Example (Conceptual – not executable)
Consider a scenario using Python and a PostgreSQL database. The following demonstrates the basic structure of a function to retrieve data:
import os import psycopg2 def handler(event, context): try: # Retrieve database connection details from environment variables db_host = os.environ['DB_HOST'] db_name = os.environ['DB_NAME'] db_user = os.environ['DB_USER'] db_password = os.environ['DB_PASSWORD'] # Establish a database connection conn = psycopg2.connect(host=db_host, database=db_name, user=db_user, password=db_password) cur = conn.cursor() # Execute a query cur.execute("SELECT- FROM users WHERE id = %s", (event['user_id'],)) rows = cur.fetchall() # Process the results if rows: user_data = 'id': rows[0][0], 'name': rows[0][1] else: user_data = None # Close the connection cur.close() conn.close() return 'statusCode': 200, 'body': json.dumps(user_data) except Exception as e: return 'statusCode': 500, 'body': json.dumps('error': str(e)) This example demonstrates the key steps, including establishing a connection, executing a query, processing results, and closing the connection. Error handling is included to ensure the function’s robustness.
Authentication and Authorization in Serverless APIs
Authentication and authorization are critical security measures for any API, and their importance is amplified in the context of serverless API backends. Serverless architectures, by their nature, expose API endpoints directly to the internet, necessitating robust mechanisms to verify the identity of users and control their access to resources. Without proper authentication and authorization, a serverless API becomes vulnerable to unauthorized access, data breaches, and malicious attacks, potentially leading to significant financial and reputational damage.
Importance of Authentication and Authorization
Authentication verifies the identity of a user or client attempting to access an API. Authorization determines what resources and operations the authenticated user is permitted to access. Implementing these two security layers ensures that only authorized users can interact with the API and that they can only perform the actions they are allowed to. The serverless nature of these APIs makes it especially important, since the attack surface is often larger.
Common Authentication Methods
Various authentication methods are employed in serverless APIs, each with its own strengths and weaknesses. Choosing the right method depends on the specific requirements of the API, the security posture, and the user experience desired.
- API Keys: API keys are unique, randomly generated strings that identify an application or user. They are simple to implement and commonly used for rate limiting and basic access control. However, API keys are less secure than other methods, as they can be easily compromised if exposed. For example, a weather API might use API keys to track usage and prevent abuse, providing different keys for various tiers of service.
- OAuth (Open Authorization): OAuth is an open standard for access delegation, allowing a user to grant a third-party application access to their resources without sharing their credentials. OAuth is widely used for social login and integrating with other services. For instance, a user might authorize a mobile app to access their Google Drive files without providing their Google password.
- JSON Web Tokens (JWT): JWTs are a compact and self-contained way for securely transmitting information between parties as a JSON object. They are often used for stateless authentication, where the server does not need to store session information. A JWT typically contains a header, a payload (containing user claims), and a signature. The signature verifies the integrity of the token. JWTs are commonly used in Single Page Applications (SPAs) and mobile apps.
- OpenID Connect (OIDC): OIDC is an authentication layer built on top of OAuth 2.0. It provides a standardized way to verify the identity of end-users based on the authentication performed by an Authorization Server, as well as to obtain basic profile information about the end-user in an interoperable and REST-like manner. It allows for more advanced features such as user profile management and single sign-on (SSO).
Simple Authentication Flow Design
A simple authentication flow for a serverless API might involve the following steps, often leveraging various cloud provider services:
- User Registration/Login: The user interacts with a client application (e.g., a web app or mobile app) to register or log in. This typically involves providing a username and password or using a social login provider.
- Credential Verification: The client application sends the user’s credentials to the serverless API. A serverless function (e.g., a Lambda function in AWS) is triggered to verify the credentials against a data store (e.g., a database like DynamoDB, or a user directory service like Cognito).
- Token Generation (if successful): If the credentials are valid, the serverless function generates a JWT (or a similar token). This token typically includes information about the user (e.g., user ID, roles).
- Token Return: The serverless function returns the JWT to the client application.
- Subsequent API Requests: For all subsequent API requests, the client application includes the JWT in the `Authorization` header (e.g., `Authorization: Bearer
`). - Authorization Enforcement: Each API endpoint has a corresponding serverless function. When an API request is received, the function verifies the JWT, extracts the user’s identity and roles, and then determines if the user is authorized to access the requested resource or perform the requested operation. This is typically achieved by using a library or framework that handles JWT validation and authorization checks.
This flow can be implemented using various technologies, such as:
- API Gateway: Acts as the entry point for all API requests, handling routing, authentication, and authorization.
- AWS Lambda (or equivalent): Serverless functions that handle credential verification, token generation, and business logic.
- Cognito (or similar): A managed user directory service that handles user registration, authentication, and authorization.
- DynamoDB (or similar): A NoSQL database for storing user data and other application data.
- JWT Libraries: Libraries (e.g., `jsonwebtoken` in Node.js, or libraries in other languages) for creating, verifying, and decoding JWTs.
This approach provides a scalable, secure, and cost-effective solution for authenticating and authorizing users in a serverless API backend. For example, a SaaS platform for project management might use this flow to allow users to log in, create projects, and manage tasks, ensuring that each user can only access the projects they are authorized to view or modify.
Monitoring and Debugging Serverless APIs

Monitoring and debugging are critical practices for maintaining the health, performance, and reliability of serverless API backends. The ephemeral nature of serverless functions, coupled with the distributed architecture, presents unique challenges. Without robust monitoring and debugging capabilities, identifying and resolving issues becomes significantly more difficult, potentially impacting application availability and user experience. Effective monitoring allows for proactive identification of performance bottlenecks, error detection, and resource optimization, while debugging tools provide the means to trace the execution flow, understand the root cause of errors, and rapidly implement fixes.
Importance of Monitoring and Debugging in Serverless Backends
Serverless architectures inherently demand a different approach to monitoring and debugging than traditional, more monolithic systems. Due to the distributed and event-driven nature of serverless functions, monitoring becomes paramount for several reasons.
- Real-time Visibility: Serverless applications often scale dynamically, making it crucial to have real-time visibility into function invocations, execution times, and error rates. This allows for immediate detection of performance degradation or service disruptions.
- Distributed Tracing: Debugging in a serverless environment requires the ability to trace requests across multiple functions and services. Distributed tracing tools provide a comprehensive view of the request lifecycle, enabling developers to pinpoint the source of errors or performance issues.
- Cost Optimization: Monitoring resource utilization, such as memory and execution time, allows for optimizing function configurations and preventing overspending. This is particularly important in serverless environments where costs are directly tied to resource consumption.
- Automated Alerting: Setting up automated alerts based on predefined metrics, such as error rates or latency, allows for proactive notification of issues. This enables rapid response and minimizes the impact of service disruptions.
- Compliance and Security: Monitoring also aids in compliance and security efforts. It provides insights into function execution logs, security events, and API access patterns, facilitating auditing and security incident response.
Tools and Techniques for Monitoring Serverless Function Performance
Effective monitoring of serverless function performance relies on a combination of tools and techniques. The choice of tools often depends on the serverless platform being used (e.g., AWS Lambda, Azure Functions, Google Cloud Functions). However, the core principles remain consistent.
- Metrics Collection: Collect metrics such as invocation count, execution time, memory usage, error rate, and cold start duration. Most serverless platforms automatically provide basic metrics, but it is often necessary to instrument the functions with custom metrics for deeper insights. Tools like Prometheus and Grafana can be used for collecting and visualizing custom metrics.
- Logging: Implement comprehensive logging within the functions. Log important events, errors, and debugging information. Structure logs using formats like JSON to facilitate parsing and analysis. Centralized logging services, such as CloudWatch Logs (AWS), Azure Monitor (Azure), and Cloud Logging (Google Cloud), are essential for aggregating and searching logs.
- Distributed Tracing: Utilize distributed tracing tools to track requests across multiple functions and services. Popular options include AWS X-Ray, Azure Application Insights, and Google Cloud Trace. These tools provide visualizations of request flows, identify bottlenecks, and pinpoint the source of errors.
- Alerting and Notifications: Set up alerts based on predefined thresholds for critical metrics. Configure notifications to be sent to relevant teams via email, SMS, or other channels. This enables proactive response to issues before they impact users.
- Performance Profiling: Employ performance profiling tools to identify performance bottlenecks within functions. These tools can help pinpoint slow code paths, inefficient database queries, or other performance-related issues. Profiling tools are often integrated with the serverless platform or can be used as standalone solutions.
- Synthetic Monitoring: Implement synthetic monitoring to simulate user interactions and proactively test API endpoints. This can help identify performance issues or outages before users are affected. Synthetic monitoring tools can automatically test API availability, response times, and functionality.
Visual Representation of a Monitoring Dashboard for a Serverless API
A well-designed monitoring dashboard provides a comprehensive overview of the serverless API’s health and performance. The dashboard should present key metrics in an easily digestible format, allowing for quick identification of issues and trends.
Dashboard Description:
The dashboard is a web-based interface, displayed on a dark gray background with a consistent layout. The top section displays a header with the API name (“My Serverless API”) and a time range selector (e.g., “Last 15 minutes”, “Last hour”, “Last 24 hours”, “Custom”).
Below the header, the dashboard is divided into several key sections:
- Invocation Metrics: A large, clear gauge showing the total number of API invocations within the selected time range. Beneath this, a line chart displays the invocation count over time, showing hourly trends.
- Error Rate: A section displaying the percentage of failed API requests. This section includes a numerical display of the error rate (e.g., “2.5% Errors”) and a line chart showing the error rate over time. Different colors (e.g., red for high error rates, green for low) are used to highlight the severity of the errors.
- Latency Metrics: A section dedicated to latency, showing the average response time for API requests. This includes a numerical display of the average latency (e.g., “350ms Average”) and a line chart showing the average latency over time. Additionally, a percentile chart (e.g., P95) provides insights into worst-case scenarios.
- Function-Specific Metrics: This section displays performance metrics for individual serverless functions. Each function has its own panel displaying metrics such as execution time, memory usage, and error count. These panels might include bar charts and numerical displays. For example, one panel might show the average execution time for the “createUser” function, with a bar chart illustrating the execution time distribution. Another panel might display the memory usage of the “processOrder” function.
- Alerts and Events: A section that displays a list of active alerts and recent events. This section would highlight critical alerts (e.g., high error rates, excessive latency) in a prominent color, such as red. It would also include information on the event timestamp, the function affected, and the alert message.
Data Presentation:
- Color Coding: Consistent use of color coding (e.g., red for errors, green for successful operations, blue for informational messages) to visually emphasize important information.
- Tooltips: Hovering over data points on charts reveals detailed information (e.g., specific values at a particular time).
- Dynamic Updates: The dashboard automatically refreshes at regular intervals (e.g., every 15 seconds) to display the latest data.
Underlying Technologies:
The dashboard is designed to be scalable and adaptable to the specific needs of the serverless API. It would likely be built using a combination of technologies, including:
- Data Collection: Serverless platform’s native monitoring tools (e.g., AWS CloudWatch, Azure Monitor) or a dedicated monitoring service (e.g., Datadog, New Relic) to collect metrics and logs.
- Data Storage: Time-series databases (e.g., InfluxDB) or cloud-native solutions (e.g., AWS CloudWatch Metrics) to store and manage metric data.
- Visualization: A dedicated dashboarding tool (e.g., Grafana, Kibana, or the monitoring service’s built-in dashboards) to visualize the data and create interactive dashboards.
Closing Summary
In conclusion, what is a serverless API backend represents a paradigm shift in application development. By abstracting away server management, it empowers developers to build scalable, cost-effective, and highly available APIs. From understanding the fundamental components to exploring different architectures and choosing the right platform, the journey into serverless API backends offers significant advantages. As the cloud continues to evolve, serverless technologies will undoubtedly play an increasingly important role in shaping the future of software development.
Frequently Asked Questions
What are the primary benefits of using a serverless API backend?
Serverless APIs offer several advantages, including automatic scaling, reduced operational costs, and increased developer productivity. They eliminate the need for server management, allowing developers to focus on code rather than infrastructure.
How does the cost model of serverless differ from traditional server deployments?
Serverless platforms typically operate on a pay-per-use model, where you are charged only for the actual compute time and resources consumed. Traditional server deployments often involve fixed costs, regardless of actual usage, leading to potential overspending during periods of low traffic.
What are some common use cases for serverless API backends?
Serverless APIs are well-suited for a variety of use cases, including web and mobile application backends, IoT device data processing, event-driven applications, and microservices architectures.
What security considerations are important for serverless API backends?
Security in serverless APIs involves implementing authentication and authorization mechanisms, securing API gateways, and protecting data storage. Utilizing API keys, OAuth, and other security protocols are crucial.